
In this post I’ll be exploring some of the challenges with embedding generative AI capabilities within a conventional software application. By conventional I mean traditional applications that rely on structured programing, deterministic rules, and operate on pre-defined algorithms without incorporating AI techniques. First, a bit of background.
About NIST CSF 2.0
The NIST Computer Security Resource Center (CSRC) has long maintained one of the most respected frameworks used by cybersecurity professionals to “understand, assess, prioritize, and communicate cybersecurity risks”, the NIST Cybersecurity Framework (CSF). On February 26, 2024 they announced the availability of NIST CSF 2.0 along with supplementary resources that are all available for free from the CSRC website (https://csrc.nist.gov/news/2024/the-nist-csf-20-is-here).
This includes version 2.0 of the framework, quick start guides, resources specific to small businesses, implementation examples and more. The framework is organized around six risk management functions: Govern, Identify, Protect, Detect, Respond, and Recover. It can be tailored to help organizations of any size create and communicate a detailed view for effectively managing cybersecurity risk. It is an indispensable tool that can be used by small businesses, large enterprise, government agencies, schools; any organization regardless of size can tailor the framework to develop robust cybersecurity and risk management strategies.
Building a self assessment tool
To make the framework more accessible to smaller organizations without in-house cybersecurity expertise, we built a self-assessment web application with an integrated AI agent we called Claudio as a nod to Anthropic’s Claude family of Large Language Models. Claudio can answer questions related to NIST CSF 2.0, provide guidance needed to complete a self-assessment and generate recommendations based on a risk profile established by asking the user a few simple questions. The tool is available for free online at https://www.akouto.com/assessment/
Anthropic Claude vs OpenAI ChatGPT
During the research stage, two competing implementations were developed: one using the OpenAI Assistant API, and the other using Anthropic’s Claude AI on AWS Bedrock. Claude quickly became the clear winner with a more intuitive API and better response times. Claude was also better at interpreting and following prompts. Even with Claude’s advantages there were still some interesting discoveries while trying to integrate generative AI with traditional software.
Application Design
Users interact with Claudio through an HTML form. Every interaction is an HTTP POST where the user submits their question (or answers to Claudio’s questions) using a basic HTML form. The web application is written in PHP, and the form data is handled by a Form Processor which performs the security checks and input validation.
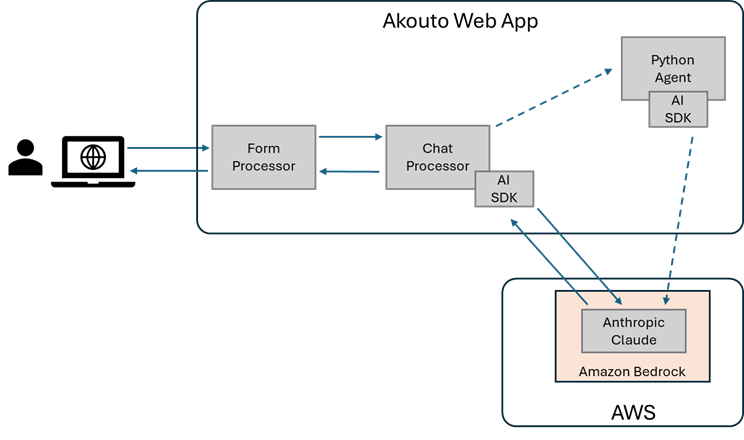
Rather than have the Form Processor directly interact with the AI API, an intermediate Chat Processor was implemented. This is where Claudio lives, it’s where the AI prompts are created to interact with AWS Bedrock and the LLM using the SDK provided by Amazon.
Another approach using a Python daemon was implemented to evaluate possible benefits of using the Python SDK instead, but since no real advantages were identified, the Python Agent approach was set aside.
Chat Processor
One of the responsibilities of the Chat Processor is to generate the prompts that are used when interacting with the LLM. The prompt is created by combining the information submitted by the user with additional inputs following a well-defined structure:
Task context: In this section we define the role and persona of Claudio the AI Cybersecurity advisor.
Tone context: In this section we instruct the LLM on the tone it will use when interacting with users.
Background data: In this section we provide information that is relevant to NIST CSF 2.0.
Rules: In this section we define the rules of engagement. We define the do’s and don’ts of Claudio’s interaction with users.
Examples: In this section we provide the LLM with concrete examples of what different interactions might look like.
Data: In this section we provide the conversation history and the user’s question (or answer)
Instructions: In this section we provide additional instructions to apply specific prompting techniques
Output formatting: In this section we provide instructions on the format of the expected response
The old and the new
One of the interesting aspects of the design approach was the ability to combine traditional software development with AI interaction to improve the overall solution including response times, accuracy rate, better understanding of context and more precise execution of tasks.
Instead of using hard-coded prompts and just appending the user input, different sections of the prompt are generated programmatically based on context. The context includes what the user is working on, past interactions, and information previously returned by Claudio among others. Tailoring the prompt for each interaction in the chat session yielded much better accuracy throughout the conversation.
To minimize opportunities for misuse, guardrails are built into rules section of the prompt. One approach would be to first submit a verification prompt to the LLM asking if any of the rules are violated before proceeding with the interaction. This approach uses significantly more tokens (and therefore costs more) and also doubles the interaction time which has a significant impact on user experience. One of the solutions was to include instructions in the input prompt for Claudio to include two distinct sections in the response: a reply to the user’s input, and a rating of the appropriateness and relevance of the input. By providing detailed instructions on the format of the response and rating sections, the Chat Processor is able to programmatically detect and mitigate misuse attempts.
XML tags proved to be extremely valuable for formatting both prompts and responses. This might be more successful with Anthropic’s Claude than other LLMs, but accuracy significantly improved by clearly identifying different sections of the input prompt using XML tags, and instructing the LLM that different sections of the response should also be delimited with XML tags to allow for post-processing by the Chat Processor. This post-processing step allows the Chat Processor to decide whether to pass through the AI response, or take some other actions depending on information contained within specific XML tags.
Risks
There’s an aspect to integrating AI with traditional software that is difficult to come to terms with from an Engineering perspective. Up to now there has not typically been room for ambiguity in software engineering. Requirements, features and functions must be well understood and are expected to work correctly 100% of the time in a completely predicable way. If they don’t, that’s a bug that needs to be fixed. With the current state of AI, this mindset just isn’t possible. Regardless of how much prompt engineering and fine tuning you do, models sometimes perform in unpredictable ways, and can even generate incorrect results. For some use cases, that’s ok as long as we’re all aware of the fact that we need to use critical thinking, verify information produced by generative AI, and be open to occasional surprises.







 Today’s small and medium businesses are increasingly a favourite target for cyber criminals. The government of Canada‘s most recent
Today’s small and medium businesses are increasingly a favourite target for cyber criminals. The government of Canada‘s most recent